Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Abstract
Large language models (LLMs) have achieved remarkable performance in recent years but are fundamentally limited by the underlying training data. To improve models beyond the training data, recent works have explored how LLMs can be used to generate synthetic data for autonomous self-improvement. However, successive steps of self-improvement can reach a point of diminishing returns. In this work, we propose a complementary approach towards self-improvement where finetuning is applied to a multiagent society of language models. A set of language models are initialized from the same base model and then are specialized by independently updating each model using data generated by the model under multiagent interaction with other models. By training each model on independent sets of data, we illustrate how this approach enables specialization across models and diversification over the set of models. As a result, our overall system is able to autonomously improve over many more rounds of fine-tuning than single-agent self-improvement methods. We quantitatively illustrate the efficacy of the approach across a wide suite of reasoning tasks.
Method
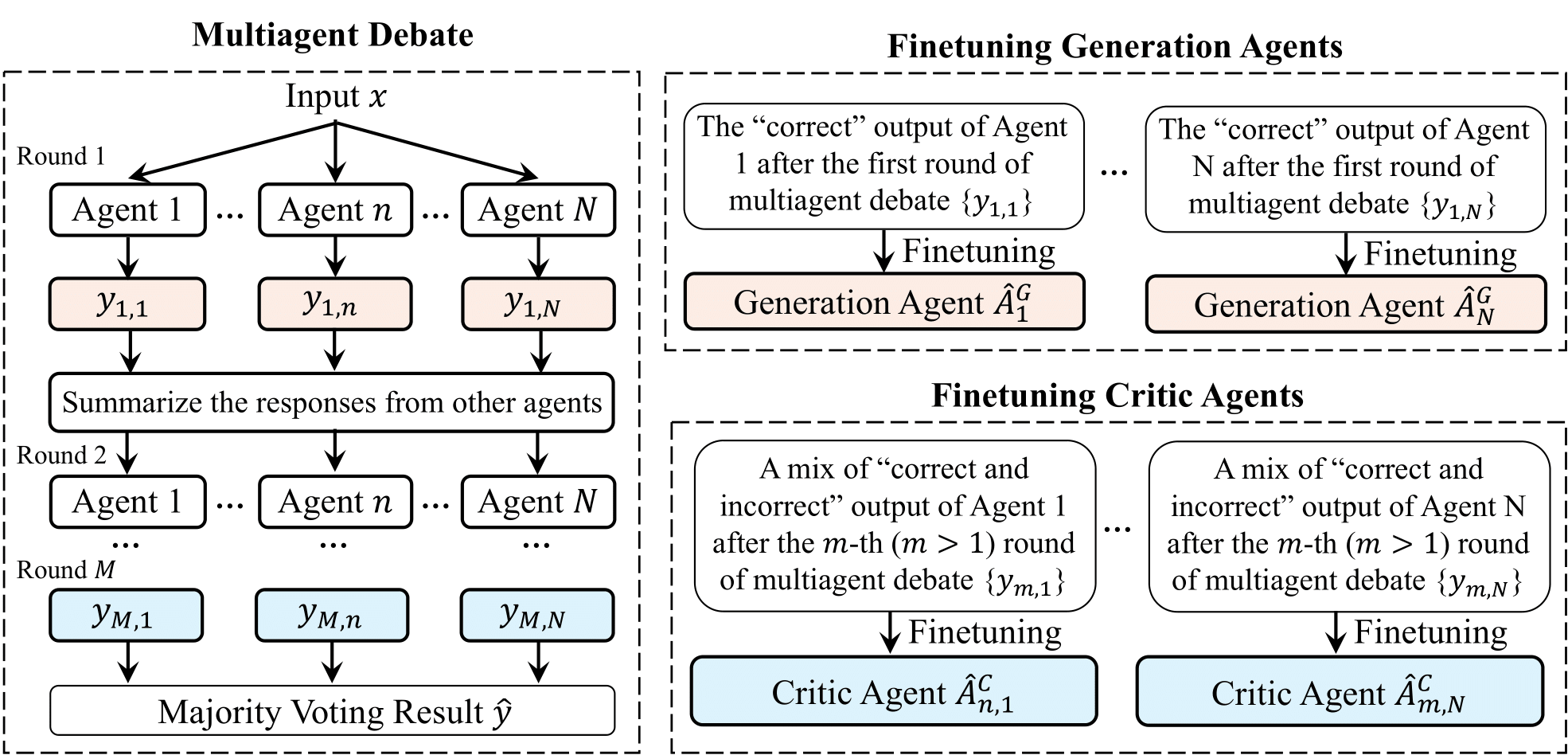
Multiagent Finetuning. Our self improvement approach constructs a multiagent set of language models over multiple rounds of finetuning. At each round of finetuning, models specialize to become generation and critic agents, and agents in each further specializing based off their generations in the previous round of finetuning.
We propose Multiagent Finetuning a new approach to self-improvement, which finetunes a multiagent set of language models from the same base model and then independently specializes each model to capture parts of a task of interest. We first use multiagent debate and majority voting to create finetuning datasets, where the final majority voted answer at the end of debate is used as the ground truth answer (left). These datasets are then used to finetune a set of generation and critic agents (right).
Finetuning Generation Agents: We finetune a set of models as "generation agents", which generate initial answers to queries. We finetune each model with the respective model's answers in the finetuning dataset that agree with final majority voted answer. By only finetuning each model on its own correctly generated answers, we allow each model to specialize over rounds of finetuning.
Finetuning Critic Agents: We finetune a set of models as "critic agents", which refine a set of initially generated answers to a more accurate final answer. We finetune each model with the respective model's answers that agree with final majority voted answer. We filter this finetuning dataset so that initial generated responses a mix of correct or incorrect answers, to teach the critic to refine both types of answers.
Inference: At inference time, we combined finetuned generation and critic models together through a multiagent debate procedure. In this figure, we illustrate a single finetuning iteration. Applying multiple rounds of finetuning iterations can significantly boost performance and encourages more specialization across models.
Self-Improvement with Multiagent Finetuning
We first study the extent to which multiagent finetuning can lead to self-improvement when compared to existing approach to self-improvement. We study both self-improvement in a single round of finetuning as well as across multiple rounds of finetuning.
What is the greatest common divisor of 315 and 108? Correct answer: 9
Generation Agent 1
Sample from Generation Agent 1 - Round 0
Generation Agent 2
Sample from Generation Agent 2 - Round 0
Generation Agent 3
Sample from Generation Agent 3 - Round 0
Critic Agent 1
Sample from Critic Agent 1 - Round 0
Critic Agent 2
Sample from Critic Agent 2 - Round 0
Critic Agent 3
Sample from Critic Agent 3 - Round 0
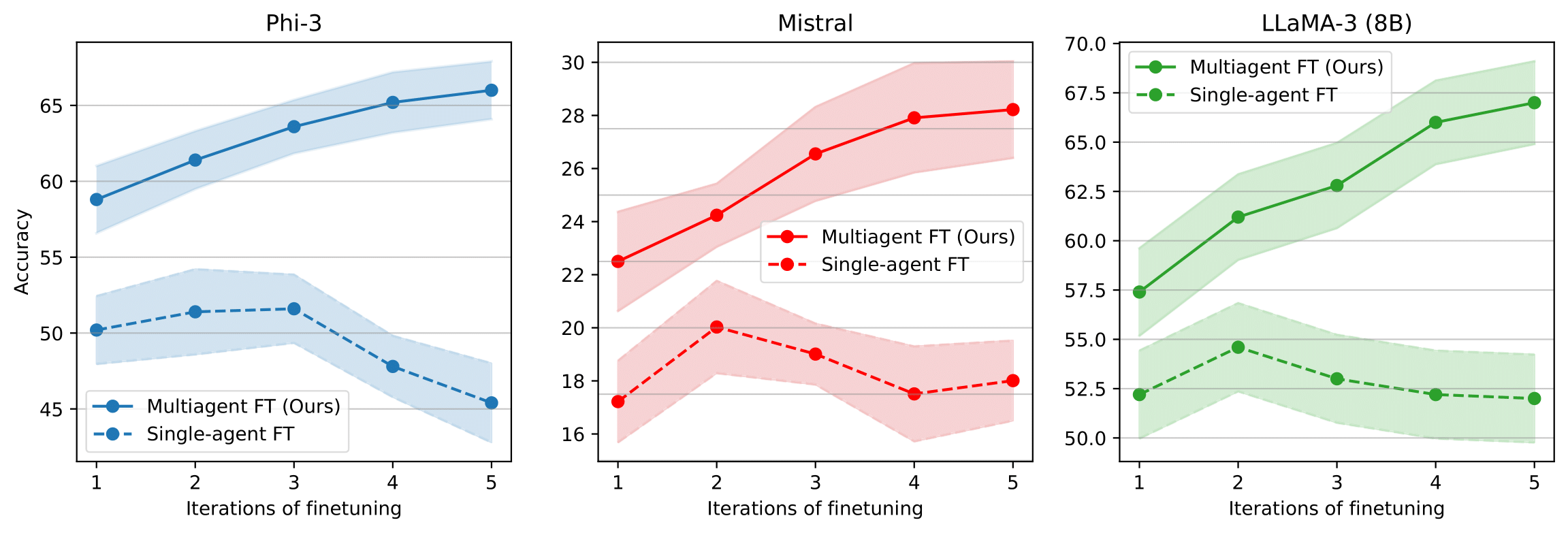
Performance after Multiple Rounds of Finetuning. Finetuning a multiagent set of models allows results to consistently improve across multiple iterations of finetuning, while finetuning a single model leads to a plateau of performance.
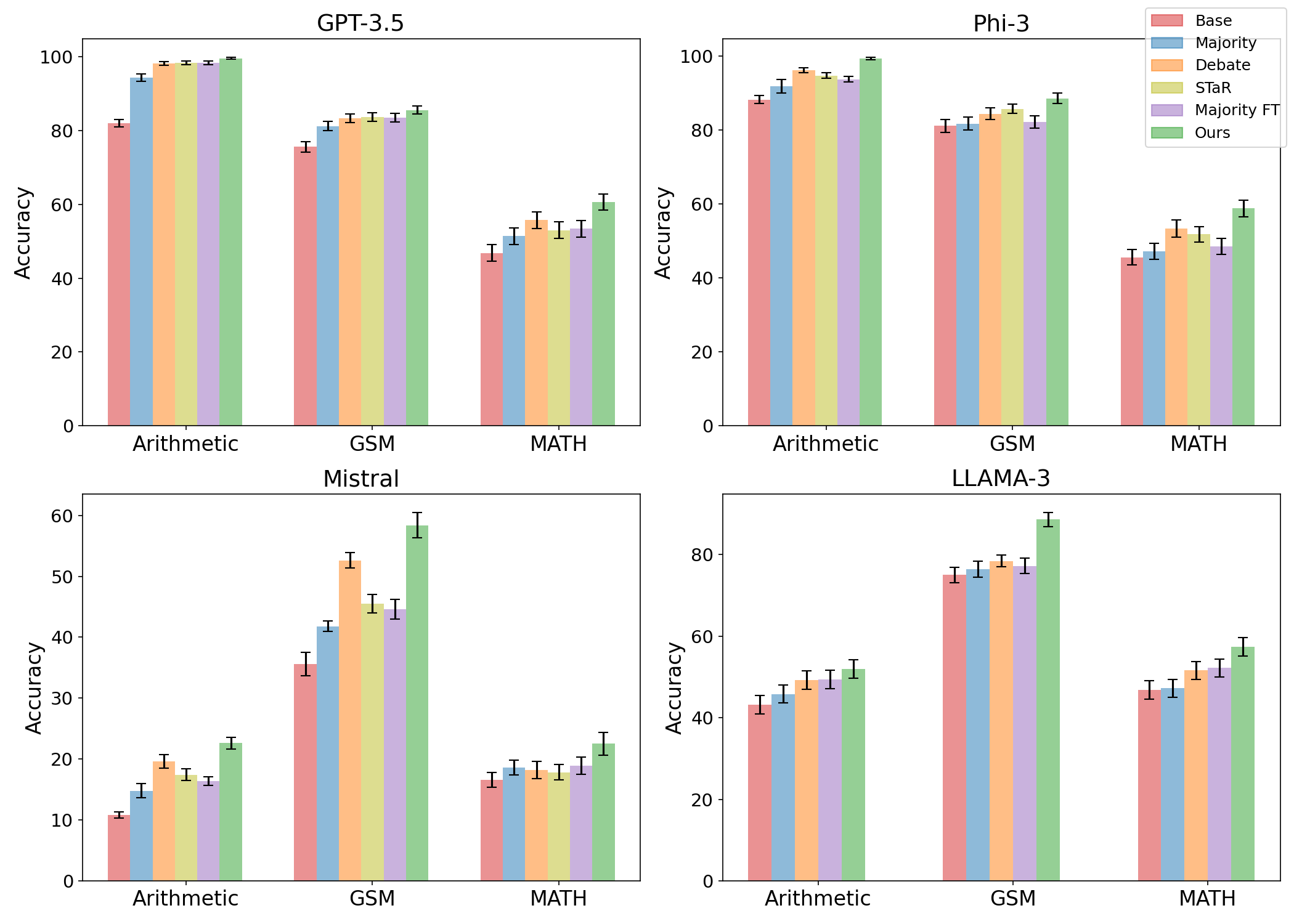
Quantitative Comparison of Self-Improvement Methods. Across for 4 different LLM models, we find that multiagent finetuning outperforms existing self-improvement methods (1 round of finetuning applied).
Preserving Diversity during Finetuning
We next study the diversity of responses after multiple rounds of finetuning. Compared to finetuning a single model, with multiagent finetuning, we preserve significantly more diversity over responses.
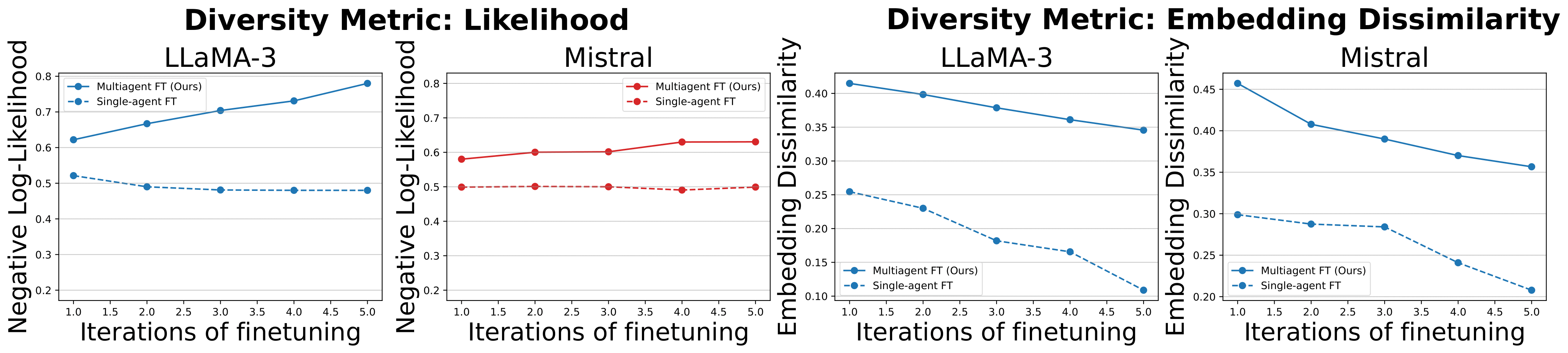
Preservering Diversity Across Rounds of Finetuning. Multiagent finetuning is able to maintain more diverse responses over rounds of finetuning than finetuning a single model.
Multiagent finetuning generalizes to new datasets
When we finetune on one dataset, we see improvement on another dataset, indicating improved generalization capabilities through multiagent finetuning.
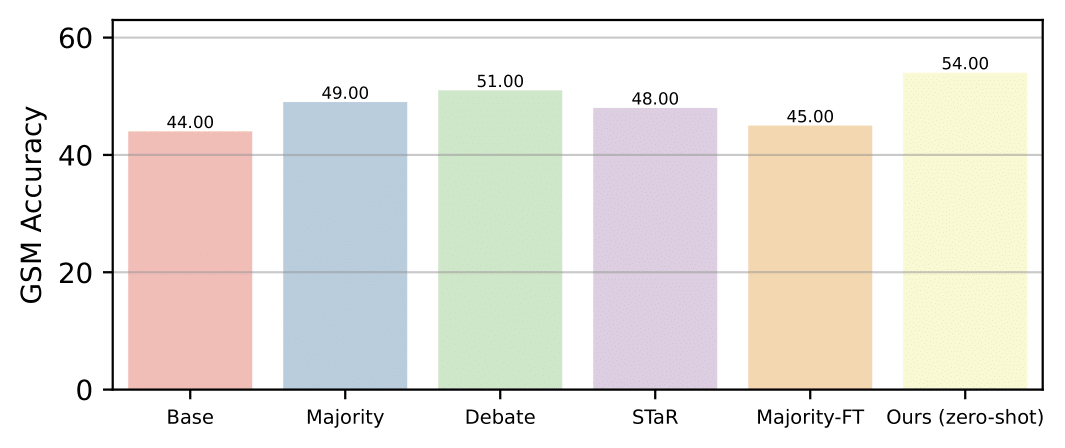
Generalization to New Datasets We assess the extend to which models that are self-improved on the MATH dataset can generalize to GSM. Multiagent finetuning has a significant improvement in performance over other finetuning methods.